Как с помощью Data Frame Pandas и programmatic увеличить LTV
- Автор: Елизавета Жук
- С чего все началось?
- 1 этап: собираем данные
- 2 этап: обработка данных
- 3 этап: проверка данных
- 4 этап: уточняем данные о покупке
- 5 этап: узнаем разницу дней между первой и последней покупкой обуви
- 6 этап: узнаем, кто покупал несколько пар обуви
- 7 этап: делаем расчеты
- 8 этап: определяем значения для каждого размера
- 9 этап: приводим в порядок, контрольно проверяем и скачиваем
- Что мы получили в итоге?
- И зачем это знать?
- Заключение
Заветное желание маркетолога — бесконечный поток клиентов. В гонке за прибылью бизнес часто делает упор на привлечение новых клиентов и совершенно забывает о тех, кто уже покупал. И это большая ошибка.
Фокус в том, что с постоянными покупателями работать гораздо проще и дешевле: их не нужно знакомить с продуктом и завоевывать доверие. Они уже знают о преимуществах бренда, качестве продуктов и более склонны к новым покупкам. По данным исследования, текущие покупатели купят новый товар с вероятностью 60-70%, а вероятность покупки среди новой аудитории всего 5-20%.

При этом важен баланс: вас не должно бросать из стороны в сторону. Нужно работать над привлечением аудитории, но и не менее важно создать группу счастливых постоянных клиентов и напоминать им о себе. Если не заниматься удержанием клиентов, то придется постоянно вливать бюджет в рекламу только для того, чтобы база клиентов не опустела. В такой ситуации рост бренда будет практически невозможен.
В этой статье рассказываем, как мы приблизились к повышению LTV с помощью DataFrame Pandas и данных клиентов о покупках.
С чего все началось?
Мы сотрудничаем с крупным российским магазином детской одежды и обуви. Основная задача всех рекламных кампаний клиента — увеличить продажи детской обуви. В запусках задействовали баннеры, нативные текстово-графические блоки, рекламу в социальных сетях и на поиске. Чтобы мотивировать аудиторию, которая уже заходила на сайт бренда, совершить покупку, подключили динамический ремаркетинг.
Хотя кампании показывали хорошие результаты, мы постоянно ищем решения, которые помогут увеличить performance-показатели. Поэтому решили протестировать гипотезу, которая может повлиять на эффективность.
Целевая аудитория клиента — родители, которым нужно часто обновлять гардероб ребенка из-за его постоянного роста и развития. Показать рекламу следующего размера через какое-то время — недостаточно. Это может быть просто не актуально — покупка новой пары обуви зависит от скорости роста стопы, а в разном возрасте она отличается. Например, детям от 4 до 8 лет обувь обновляют в среднем 2-3 раза в год, а к подростковому возрасту рост ноги замедляется и новый размер ботинок покупается реже. Команда NT задалась вопросом: “А что если узнать период между повторными покупками, сегментировать аудиторию на основе этих данных и показать персонализированный креатив с напоминаем о покупке следующего размера?”
Проверяли гипотезу поэтапно: сначала узнавали закономерности программно, разрабатывали медиастратегию с учетом статистики и потом тестировали на практике. Ниже рассказываем подробнее.

1 этап: собираем данные
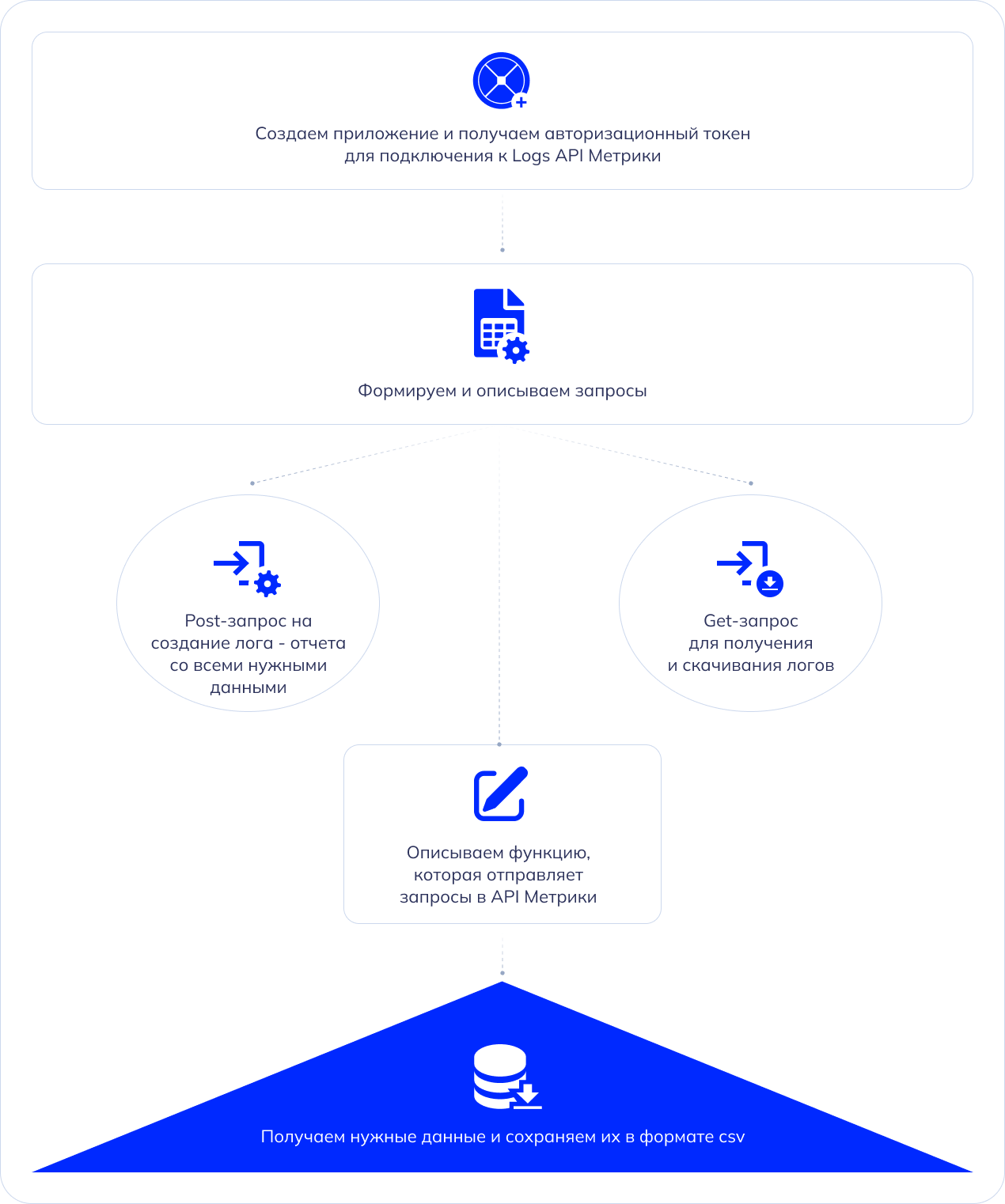
Основа исследования — сырые данные, записи об отдельных визитах или просмотрах. Таблица с этими записями передается через Logs API Яндекс.Метрики, при этом каждая запись дополняется полезными сведениями (информация из электронной коммерции, технические сведения о визите и не только).
Чтобы получить нужную информацию, описали функцию, которая подключается к API метрики и отправляет запросы на получение данных. Структура кода выглядит так:

После этого подготовили post-запрос, который создает лог — отчет, в котором будет нужная нам информация. Структура выглядит так:

- Counter — идентификатор счетчика Яндекс.Метрики клиента;
- date1 — дата начала отчетного периода в формате;
- date2 — дата конца отчетного периода;
- fields — список полей, которые надо получить;
- f — будущий файл csv, который мы будем скачивать.
Поля — это те параметры визитов, которые Метрика выгрузит из базы данных и предоставит нам в виде файла в формате CSV. Нас интересовало получение следующей информации:
- PurchaseID;
- VisitID;
- ClientID;
- PurchaseDateTime — дата и время покупки;
- ProductsName — название покупки;
- ProductsCategory — какой категории покупка;
- ProductsQuantity — количество покупок.
Следующий шаг — написать get-запрос, чтобы скачать подготовленный лог. Он выглядит так:

Параметры запроса:
- CounterId — идентификатор счетчика;
- partNumber — номер части подготовленных логов обработанного запроса;
- requestId — идентификатор запроса логов;
- part 0/1 — порядковый номер той части лога, которую нужно скачать;
- f — будущий файл csv, который мы будем скачивать.
Логи в Яндекс.Метрике состоят из двух частей. Первую часть мы сохраняем в file0, а вторую — в file1. Затем создаем пустой csv файл с помощью конструкции “with open(“part.csv”, “w”) as f”, а с помощью команд “f.write(file0)” и “f.write(file1)” записываем данные из двух частей логов в наш дата фрейм и скачиваем его.
2 этап: обработка данных
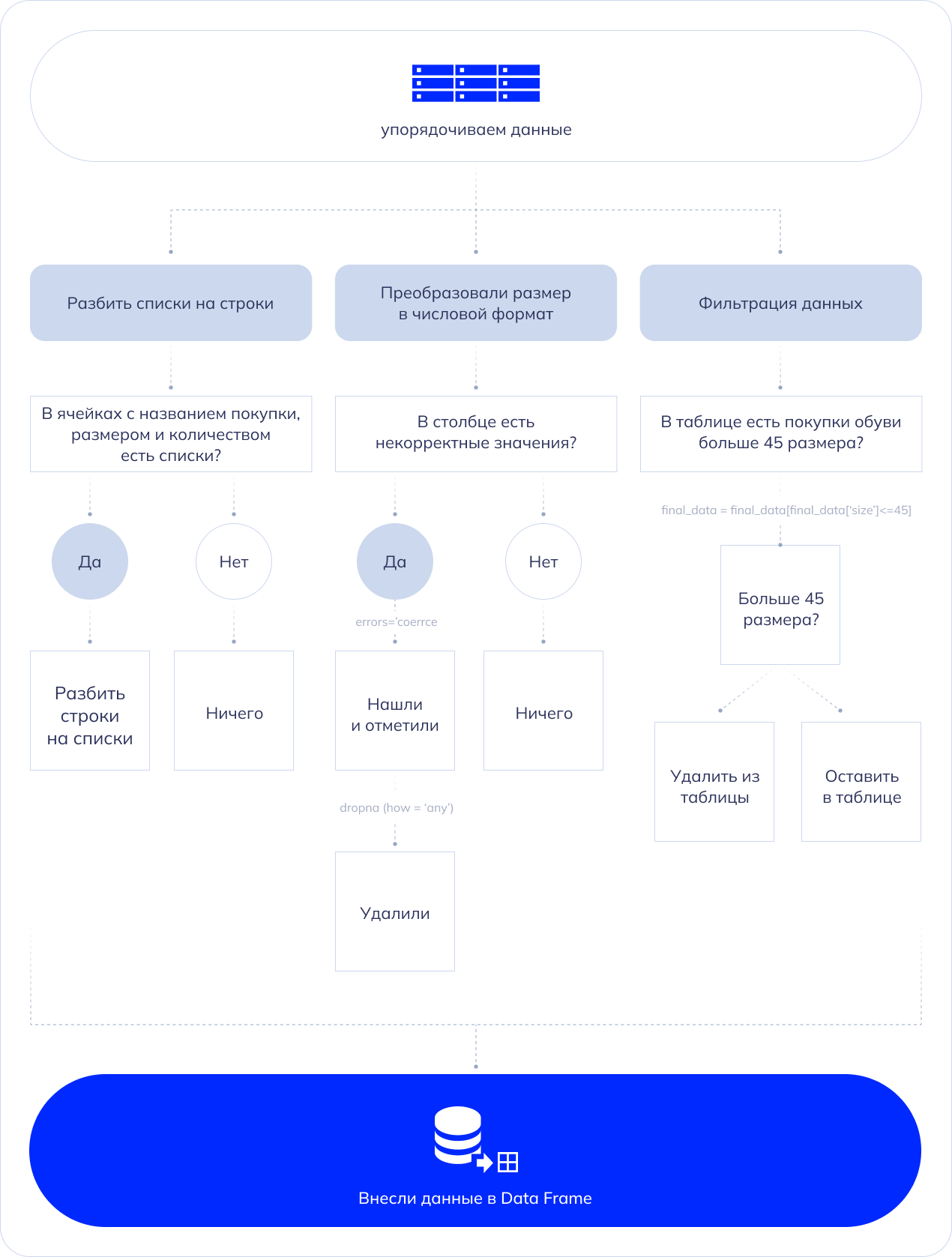
На предыдущем этапе мы получили список с нужной информацией. Чтобы привести данные в удобный для анализа вид, мы создали data frame (df). Это высокоуровневая структура данных, которые организованных в строках и столбцах. В строках дата фрейма могут быть списки. Чтобы разбить такие списки на строки, использовали функцию explode — она предназначена для преобразования столбцов со вложенными списками в отдельные строки с повторением значений в других столбцах. Это помогает упростить структуру для дальнейшего анализа. Структура кода выглядит так:

Продолжая работать с агрегированными данными мы:
- Преобразовали столбец “Размер” в числовой формат. После конвертации одного формата в другой, могут возникать ошибки. Поэтому с помощью параметра “errors=’coerce’” нашли такие ячейки и поставили вместо некорректного значения пустое.
- Чтобы удалить строки с пустыми значениями, использовали метод dropna. С помощью параметра “how=’any’” указали методу удалять строки, где хотя бы один элемент пустой.
В массивах и списках элементы часто упорядочены по порядковому номеру, который называется индексом. В строках также каждый элемент имеет свой индекс. После удаления строк в data frame индексы могут быть разрозненны. Чтобы этого избежать, мы сбросили индексы строк и создали новые с помощью команды “final_data. reset_index(drop=True)”.
С помощью функции lambda в столбце “purchaseDateTime” оставили первое дату и время покупки, если было их несколько. Следующим шагом с помощью dt.date преобразовали значения в этом столбце в объекты типа date, оставив только информацию о дате покупке, исключив время. С помощью final_data = final_data[final_data[‘size’] <= 45] применили команду фильтрации и оставили в таблице только те строки, где значения размера обуви не превышают 45.

3 этап: проверка данных
Чтобы убедиться в отсутствии ошибок, мы проверили распределение размеров по количеству наблюдений в поисках выбросов. В статистике выбросы — это значения, которые резко отличаются от других значений в наборе данных. Они могут привести к искажению результатов исследования. Исключив их, мы придем к более точным выводам.
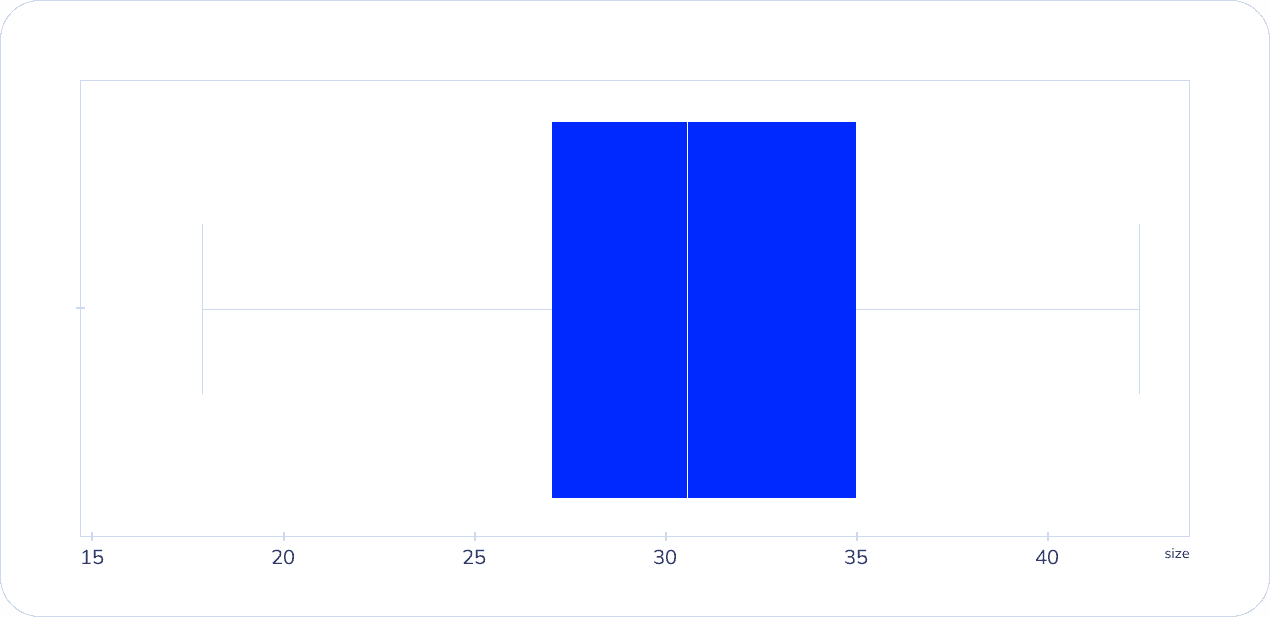
Их легко обнаружить в таблицах значений и на графиках. Мы выбрали второй вариант — проверять будем с помощью гистограммы и диаграммы размаха (ящик с усами).
С помощью функции sns.boxplot(final_data[‘size] создали “ящик с усами” для столбца с размером обуви. Чтобы отобразить диаграмму, использовали команду plt.show().Вот, что у нас получилось:
Для создания гистограммы распределения значений столбца “Размер обуви” , использовали функцию plt.hist. С помощью аргументов final_data[‘size’] и bins=20, обозначили для какого столбца нужен график и задали количество интервалов — 20. Для отображения гистограммы использовали plt.show(). Структура кода и гистограмма выглядят так:

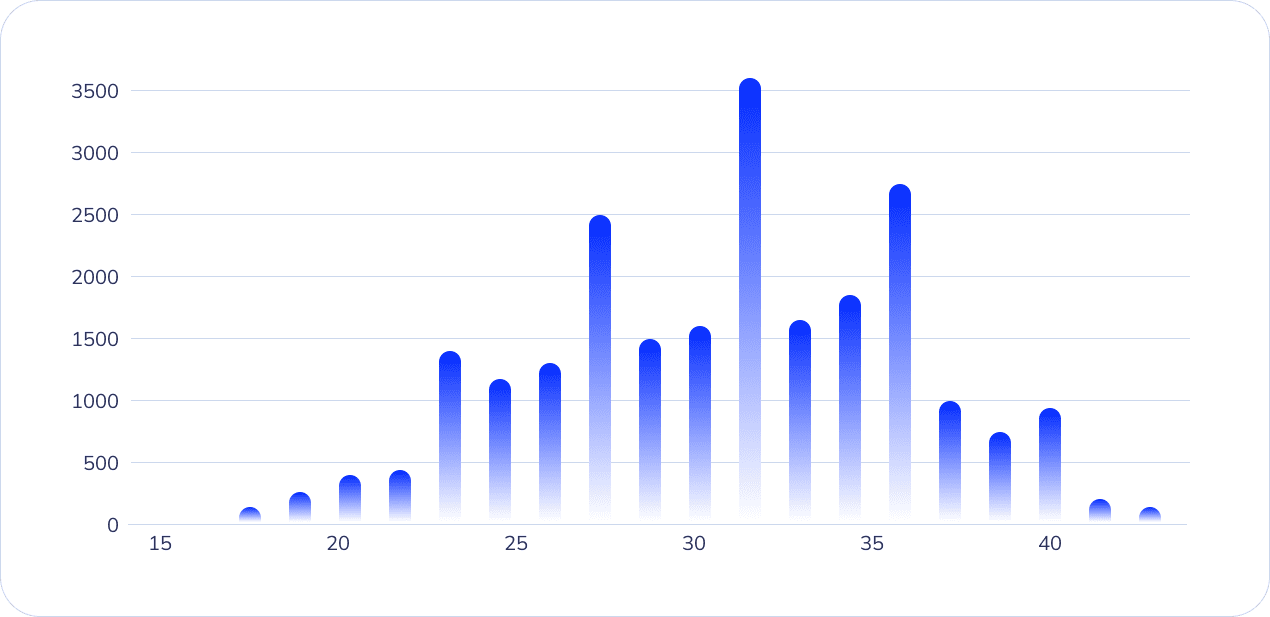
Так мы убедились, что выбросов в исследовании нет. В дальнейшем мы будем проверять таблицу каждый раз, когда будем применять функции фильтрации к ее данным.
4 этап: уточняем данные о покупке
Основная задача этапа — узнать дату первой и последней покупки детской пары обуви в магазине клиента. Структура кода выглядит так:

Для получения нужной информации использовали функцию groupby. Она позволяет разбивать данные на группы на основе определенного критерия и применять к каждой группе операции агрегации, трансформации или фильтрации.
В нашем коде мы сгруппировали данные по столбцам “ClientID” и “Size”. После этого с помощью “agg” применили агрегационные функции к каждой группе данных (агрегационные функции — это функции, которые выполняют вычисления на наборе данных). Для столбца “PurchaseDateTime” использовали функции минимума (‘min’) и максимума (‘max’), а для столбца PurchaseID — count, чтобы посчитать количество записей в наборе данных. Таким образом, для каждой группы (‘clientID’, ‘size’) мы узнали дату первой и последней покупки и количество покупок.
С помощью кода “last_df = groupped.reset_index(drop=False)” сбросили индексы в файле со сгруппированными данными и создали новую табличку, куда перенесли всю информацию — last_df. Параметр “drop=False” указывает, что индексы не просто удаляются, а также переносятся в новый дата фрейм.

5 этап: узнаем разницу дней между первой и последней покупкой обуви
Структура кода этого этапа выглядит следующим образом:

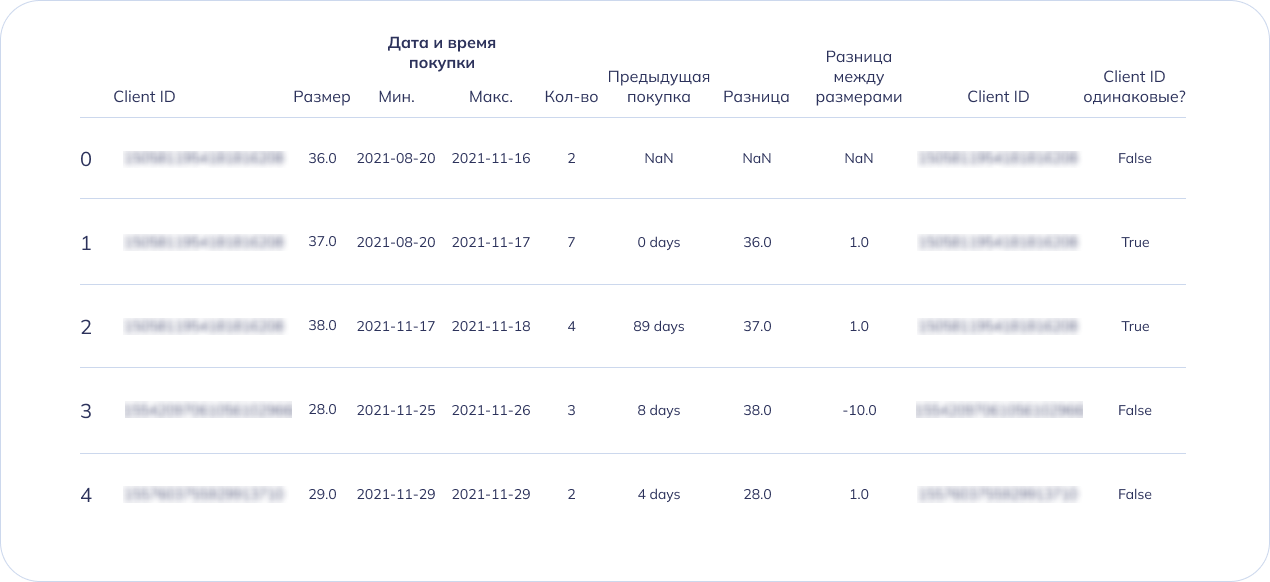
На этом этапе мы создали новые столбцы в новом df, в которые вносятся значение предыдущей строки этого столбца, а также разница для каждой строки.
В целом алгоритм действия на этом этапе выглядит так:
- 1-я строка кода: с помощью команды shift сдвигает дату на одну строку;
- 2-я строка кода: находит разницу дат, т.е. количество дней до следующей покупки;
- 3-я строка кода: сдвигает данные о размере;
- 4-я строка кода: находит разницу размеров;
- 5-я строка кода: сдвигает ClientID покупателя;
- 6-я строка кода: ставит True если клиент прошлой строки и следующей одинаковый или False если разный.
Таким образом мы узнали через сколько дней клиенты покупали следующую пару обуви, а также разницу размеров между прошлой и новой покупкой. Чтобы визуально проверить результат в таблице применили функцию last_df.head(), чтобы отобразить часть файла:
6 этап: узнаем, кто покупал несколько пар обуви
Чтобы продолжить исследование нам нужно оставить данные, которые относятся к одному и тому же клиенту — то есть ClientID с пометкой “True” в таблице. При этом оставить в таблице только тех, кто купил детскую обувь следующего размера.
Эти данные уже есть в таблице, их нужно только “достать и упорядочить”. Идея состояла в том, чтобы отфильтровать данные по true/false для ClientID, разнице между размерами купленной обуви и датой следующей покупки. После этого удалить ненужную информацию. Это сделали с помощью этого кода:

Параметры фильтрации:
- last_df[‘size_difference’] == 1 — код выберет только те строки, где значение в столбце “Size_Difference” (Разница между размерами обуви) равна 1, т.е. пользователь купил пару обуви на один размер больше;
- last_df[‘difference’] > ‘0 days’ — код выберет строки, где разница между покупками больше 0 дней;
- last_df[‘is_same_clientID’] == True — выбираются те строки, где в столбце с ID клиента есть пометка “True”, то есть следующую пару обуви приобрел один и тот же клиент.
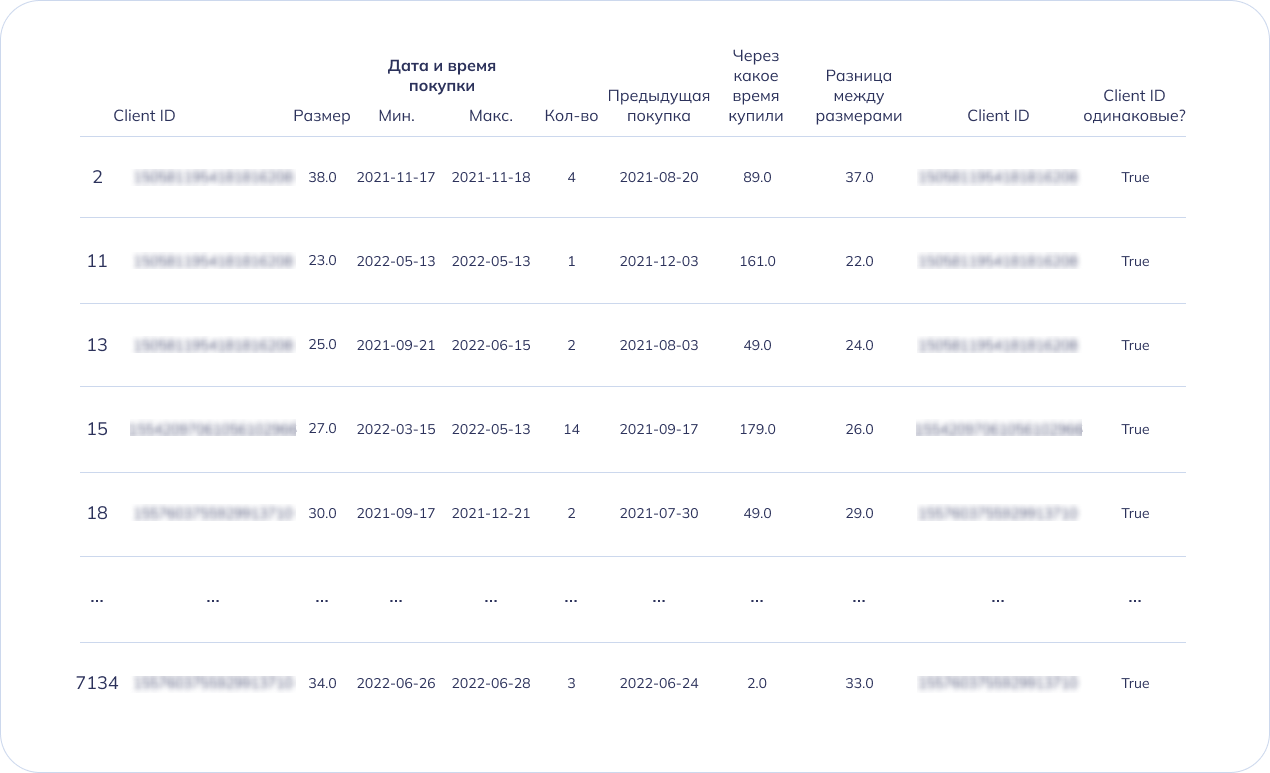
Мы объединили условия фильтрации с помощью [(…)] и значка &. Если строки соответствуют всем условиям, они попадают в новый data frame — filtered. Получилась такая таблица:
7 этап: делаем расчеты
Следующий шаг — рассчитать медиану, минимальный и максимальный промежуток до следующей покупки. Это делали с помощью функции, которая считает интервалы. Функцию определили с помощью “def” — она берет на вход список с данными, рассчитывает взвешенное среднее, определяет промежутки между покупками новых пар обуви и вносит эти данные в табличку. Описанная функция выглядит так:

В первой части кода мы рассчитывали квартили. Квартили — числовые значения признака, которые делят упорядоченные по возрастанию данные на четыре равных части. Их всего три: первый (нижний), второй (средний) и третий (верхний). Нам они нужны для расчета медианы и промежутков между покупками.
- order_q1 = np.quantile(lists,0.25) — вычисляет первый квартиль (Q1), ниже которого располагается 25% данных.
- order_q3 = np.quantile(lists, 0.75) — вычисляет третий квартиль (Q3), ниже которого располагается 75% данных.
- order_iqr = order_q3 – order_q1 — рассчитывает межквартильный диапазон (IQR), который охватывает центральные 50% данных.
После того как мы вычислили квартили, мы рассчитали промежутки между покупками и медиану:
- left = np.average(lists) – abs((order_iqr – np.average(lists)) / 2) — вычисляет левую границу интервала, то есть минимальный промежуток между покупкой следующей пары обуви;
- right = np.average(lists) + abs((order_iqr – np.average(lists)) / 2) — определяет правую границу диапазона, то есть максимальный промежуток между покупкой следующего размера.
Все полученные значения записали в int_result — словарь результатов, — с помощью этого кусочка кода:

Команду “int_result[‘count’] = len(lists)” использовали, чтобы записать количество пар размеров обуви в исследовании.
8 этап: определяем значения для каждого размера
С помощью функции “groupby” данные сгруппировали по размеру обуви и к группе применили агрегационную функцию lamda — в нашем коде она применяет функцию, которую мы описали в предыдущем этапе, к каждому размеру обуви из группы. В результате, мы рассчитали минимальный и максимальный промежутки между покупкой новой пары обуви и медиану для каждого размера. Все данные занесли в таблицу:
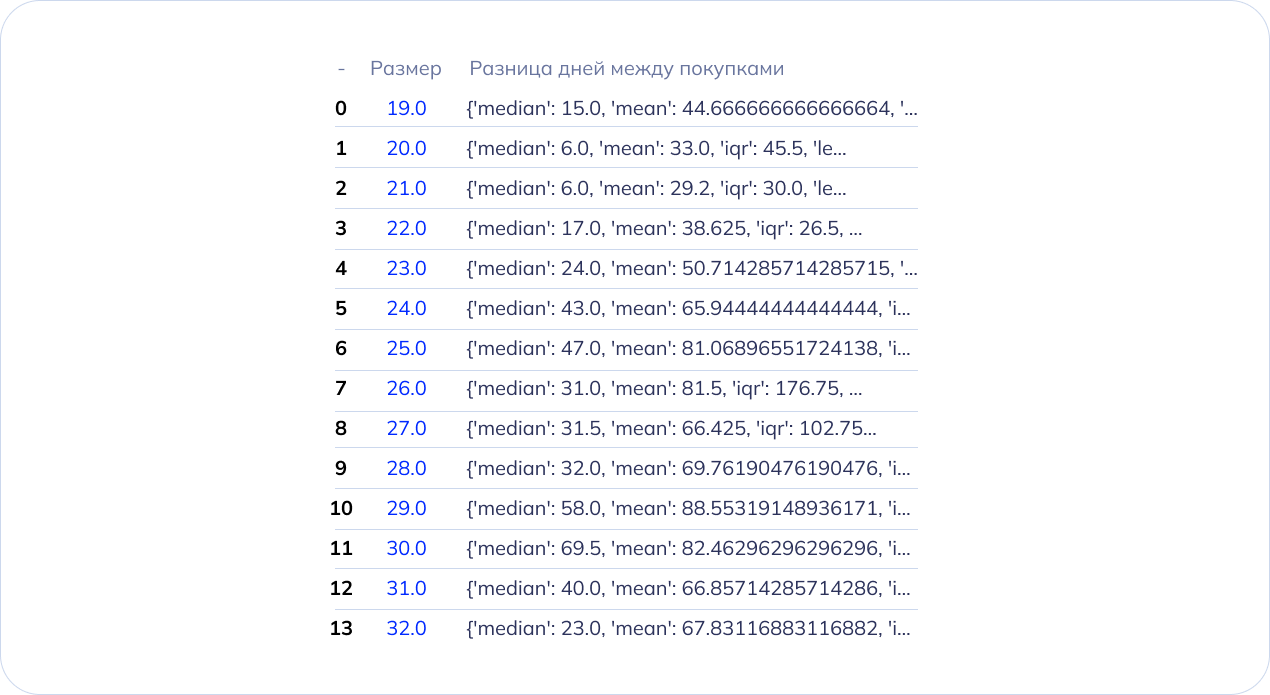
Структура кода выглядит так:

9 этап: приводим в порядок, контрольно проверяем и скачиваем
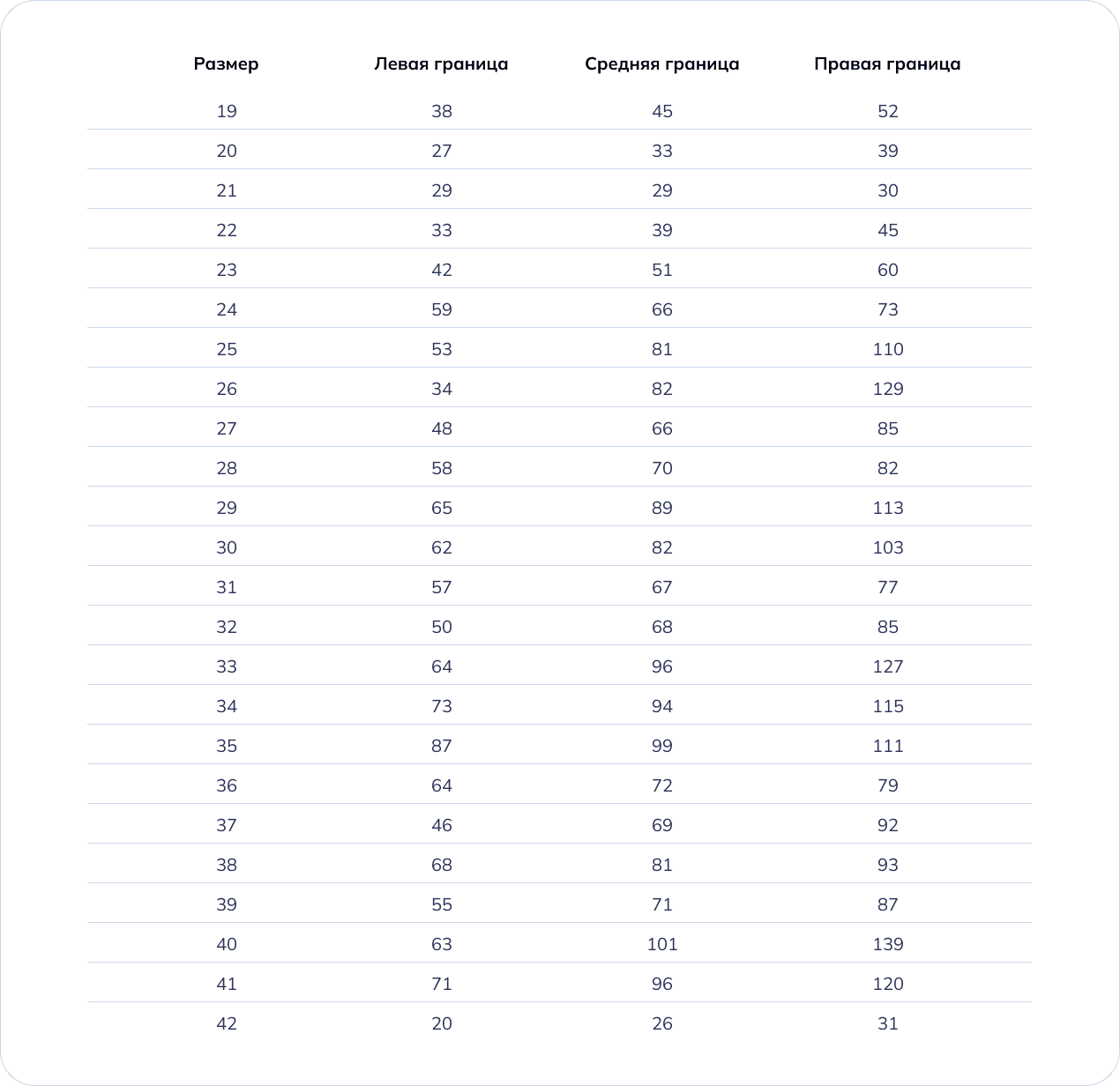
Чтобы привести таблицу в удобный вид для изучения и анализа, мы создали новый data frame с дополнительными ячейками и поместили все данные туда.
Следующим шагом проверили полученные результаты на выбросы, упорядочили и перевели в csv формат для скачивания. В итоге мы получили такой df, где:
- Размер – размер обуви;
- Левая граница – приближенное к минимальному количеству дней до покупки следующего размера;
- Средняя граница – приближенное к среднему количеству дней до покупки следующего размера;
- Правая граница – приближенное к максимальному количеству дней до покупки следующего размера.
Что мы получили в итоге?
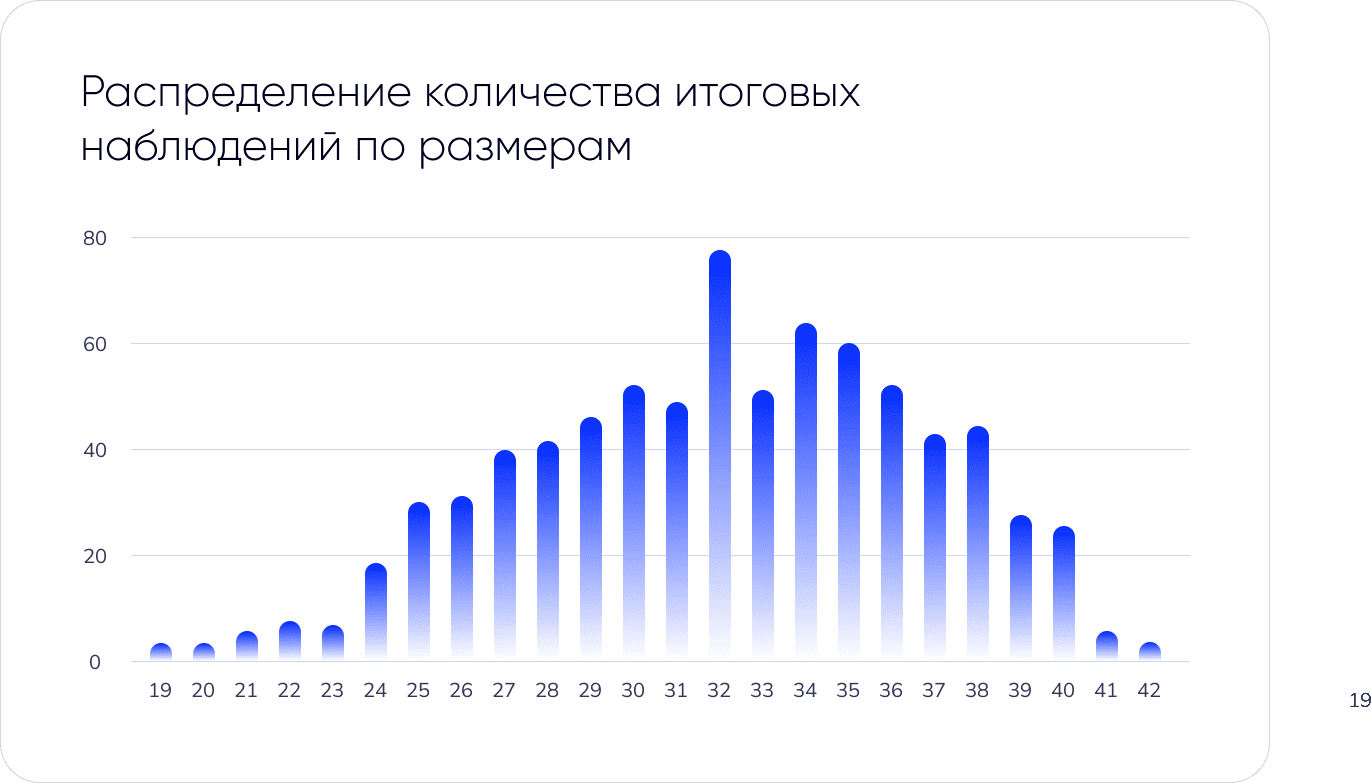
В результате исследования мы узнали окно атрибуции, через который родители покупают пару обуви следующего размера для своего ребенка в зависимости от его текущего размера стопы. Например, после покупки 22 размера обуви следующую пару купят в среднем через 67 дней. Также, по графику распределения количества итоговых наблюдений по размерам видно, что чаще всего в магазине покупают обувь 32, 34 и 35 размера. Следовательно, родители детей от 6 до 12 лет обновляют обувь чаще.
И зачем это знать?
Чтобы улучшить рекламные стратегии. Пока компании запускают рекламу в интернете, крутят по радио и ТВ, отправляют e-mail-рассылки и push-уведомления и даже по старинке закидывают буклеты в почтовые ящики, у пользователей выработался иммунитет к рекламе. Они почти не замечают баннеры, рекламные ролики скиппают и промо-посты в соцсетях пролистывают. Находит отклик только та реклама, которая попадает в запрос пользователя здесь и сейчас.
Для брендов это означает, что недостаточно увеличить бюджет в Х раз, чтобы перекрыть кампании конкурентов и обратить на себя внимание пользователей. Следует определиться: как создать персонализированное объявление, какое рекламное сообщение транслировать, на какую аудиторию в запуске делать упор и не только.

Источник: Statista
Исследование помогло закрыть эти вопросы. Учитывая полученные результаты, можно разработать account-based стратегию и показывать аудитории персонализированные сообщения. Идея в том, чтобы разбить аудиторию ремаркетинга на кастомные сегменты, разработать для каждого сегмента персонализированный креатив и показать его через определенный промежуток времени. При том сегменты аудитории и окно атрибуции выбираются на основе того, какой размер обуви приобрели родители последним, а рекламное сообщение — это напоминание, что пора купить пару большего размера. Например, для сегмента аудитории родителей, которые купили обувь 32 размера, рекламные креативы будут показаны через 50-68 дней.
Придерживаясь такой стратегии, можно взаимодействовать с покупателями магазина на протяжении всей их “жизни”: установить контакт, увеличить их количество и постоянно стимулировать конверсии, вовремя напоминая о необходимости покупки новой пары обуви. Это поможет увеличить LTV и ROI для бренда.
Заключение
Работа с данными позволяет решать разные задачи: от выстраивания коммуникации с аудиторией до привлечения максимально целевых пользователей, персонализации стратегии и оптимизации расходов на рекламу.
Мы в NT — фанаты данных и технологий и верим, что они определяют результат, как и экспертиза команды. Поэтому вместе развиваем NT Programmatic платформу, постоянно экспериментируем и помогаем достичь даже самых сложных целей с помощью автоматизированной рекламы и комплексных решений. Напишите нам сегодня, мы поможем увеличить ваш доход с помощью рекламы.